Los genes localizados en el núcleo celular controlan la síntesis de las proteínas porque contienen la información biológica necesaria para determinar la secuencia exacta de aminoácidos que formará cada proteína. Esta función constituye uno de los principios fundamentales de la biología molecular moderna y explica cómo la información genética almacenada en el ADN dirige la estructura, función, regulación y adaptación de las células. La capacidad de los genes para controlar la síntesis proteica depende de la organización molecular del ADN, de la secuencia específica de sus nucleótidos y de los mecanismos celulares que permiten copiar y traducir dicha información en moléculas funcionales.
En el núcleo de las células eucariotas, el ADN se encuentra organizado en cromosomas. Cada cromosoma está formado por una molécula extremadamente larga de ADN asociada con proteínas especializadas denominadas histonas. Estas moléculas contienen miles de genes distribuidos a lo largo de su extensión. Un gen puede definirse como una secuencia específica de ADN que contiene la información necesaria para producir una molécula funcional, generalmente una proteína, aunque algunos genes producen moléculas de ARN con funciones reguladoras. La secuencia de nucleótidos presente en cada gen constituye un código biológico capaz de almacenar información hereditaria con enorme precisión.
La molécula de ADN posee una estructura de doble hélice formada por dos cadenas antiparalelas. Cada cadena está compuesta por unidades repetitivas denominadas nucleótidos. Cada nucleótido contiene tres componentes fundamentales: un grupo fosfato derivado del ácido fosfórico, una molécula de azúcar desoxirribosa y una base nitrogenada. Las cuatro bases nitrogenadas presentes en el ADN son adenina, timina, guanina y citosina. Estas bases constituyen el verdadero lenguaje químico de la información genética, ya que la secuencia en la que aparecen determina el contenido informativo de cada gen.
El esqueleto estructural de cada hebra de ADN está formado por la alternancia regular de moléculas de fosfato y desoxirribosa unidas mediante enlaces fosfodiéster. Las bases nitrogenadas se proyectan hacia el interior de la molécula y establecen interacciones específicas entre ambas hebras. La adenina se aparea exclusivamente con la timina mediante dos enlaces de hidrógeno, mientras que la guanina se aparea exclusivamente con la citosina mediante tres enlaces de hidrógeno. Esta complementariedad garantiza la estabilidad estructural del ADN y permite la transmisión fiel de la información genética durante la replicación celular.
La disposición secuencial de las bases constituye el elemento esencial que permite a los genes controlar la síntesis proteica. Aunque todas las moléculas de ADN están construidas con los mismos cuatro nucleótidos, la enorme diversidad de secuencias posibles permite almacenar cantidades extraordinarias de información biológica. Cada gen posee una secuencia característica que especifica una proteína determinada. Por esta razón, la información genética no depende de la composición química general del ADN, sino del orden preciso de sus nucleótidos.
La estructura de doble hélice facilita el acceso a la información genética cuando la célula necesita utilizar un gen. Los enlaces de hidrógeno que mantienen unidas ambas cadenas son relativamente débiles en comparación con los enlaces covalentes del esqueleto fosfodiéster. Esta característica permite que las dos hebras se separen localmente mediante la acción de enzimas especializadas. La separación temporal de las cadenas resulta indispensable para procesos como la replicación y la transcripción.
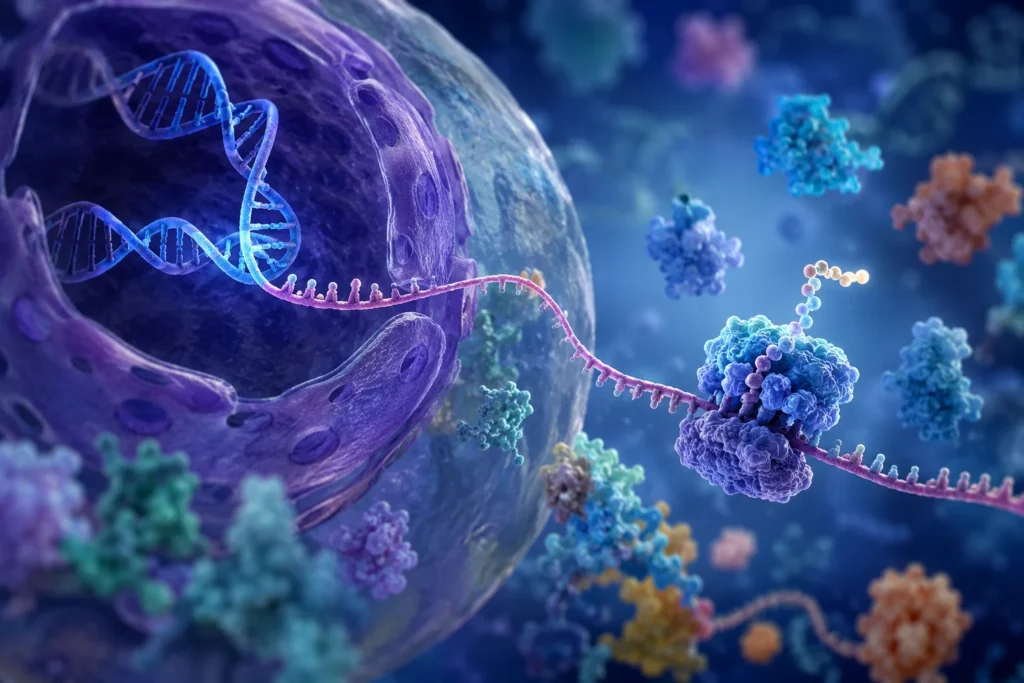
El primer paso mediante el cual un gen controla la síntesis de proteínas es la transcripción. Durante este proceso, una región específica del ADN se desenrolla y una de las dos hebras actúa como molde para sintetizar una molécula complementaria de ARN mensajero. La enzima responsable de esta función es la ARN polimerasa. Esta enzima reconoce secuencias reguladoras específicas situadas al inicio de los genes y comienza la incorporación ordenada de ribonucleótidos complementarios a la hebra molde.
Durante la transcripción, las reglas de complementariedad se conservan parcialmente. La adenina del ADN se aparea con uracilo en el ARN, mientras que la timina, ausente en el ARN, es sustituida por esta base. La guanina continúa apareándose con citosina y la citosina con guanina. Como resultado, se genera una copia temporal de la información genética contenida en el gen. Esta molécula de ARN mensajero transporta la información desde el núcleo hacia el citoplasma.
En organismos eucariotas, el ARN recién sintetizado experimenta un proceso de maduración antes de abandonar el núcleo. Durante este proceso se eliminan regiones no codificantes denominadas intrones y se unen las regiones codificantes llamadas exones. Además, se añaden modificaciones químicas en ambos extremos de la molécula que aumentan su estabilidad y facilitan su reconocimiento por la maquinaria celular. Estas modificaciones aseguran que la información genética llegue correctamente a los ribosomas.
El segundo paso fundamental es la traducción. Este proceso ocurre en los ribosomas, complejos moleculares formados por ARN ribosómico y proteínas. Los ribosomas leen la secuencia de nucleótidos del ARN mensajero en grupos de tres bases denominados codones. Cada codón especifica un aminoácido determinado o una señal de inicio o terminación de la síntesis proteica.
El código genético constituye el sistema de correspondencia entre los codones y los aminoácidos. Está formado por 64 codones diferentes derivados de las posibles combinaciones de cuatro bases tomadas de tres en tres. De estos codones, 61 codifican aminoácidos y 3 funcionan como señales de terminación. La universalidad casi completa del código genético en todos los seres vivos constituye una de las evidencias más sólidas de un origen evolutivo común.
La traducción requiere la participación de moléculas especializadas denominadas ARN de transferencia. Cada una de estas moléculas transporta un aminoácido específico y posee una secuencia denominada anticodón que reconoce al codón correspondiente en el ARN mensajero. Cuando el anticodón se aparea con el codón apropiado, el aminoácido transportado es incorporado a la cadena proteica en crecimiento.
A medida que el ribosoma avanza sobre el ARN mensajero, los aminoácidos se unen mediante enlaces peptídicos formando una cadena polipeptídica. El orden de incorporación de los aminoácidos está determinado exclusivamente por la secuencia de codones codificada originalmente en el ADN. Por tanto, la secuencia de nucleótidos de un gen determina directamente la secuencia de aminoácidos de la proteína correspondiente.
La relación entre la secuencia genética y la secuencia proteica constituye el fundamento molecular de la expresión génica. Una alteración en la secuencia de ADN puede modificar uno o varios codones y, en consecuencia, alterar la secuencia de aminoácidos de la proteína resultante. Dependiendo de la naturaleza de la modificación, la proteína puede conservar su función, perderla parcialmente o adquirir propiedades nuevas. Este fenómeno explica la base molecular de numerosas enfermedades hereditarias y también proporciona la materia prima para la evolución biológica.
El control génico de la síntesis proteica no se limita únicamente a la secuencia codificante. Los genes poseen regiones reguladoras que determinan cuándo, dónde y en qué cantidad se producirá una proteína. Estas regiones interactúan con proteínas reguladoras, factores de transcripción y complejos epigenéticos que modulan la actividad génica. Como resultado, células que contienen exactamente el mismo ADN pueden producir conjuntos de proteínas completamente diferentes y desarrollar funciones especializadas.
La organización del ADN dentro del núcleo también participa en la regulación de la expresión génica. El grado de compactación de la cromatina influye directamente sobre la accesibilidad de los genes a la maquinaria de transcripción. Las modificaciones químicas de las histonas y la metilación del ADN pueden activar o silenciar genes específicos sin alterar la secuencia nucleotídica. Estos mecanismos epigenéticos desempeñan funciones esenciales durante el desarrollo embrionario, la diferenciación celular y la adaptación a cambios ambientales.
La precisión del control genético resulta extraordinaria. Diversos sistemas de corrección de errores supervisan tanto la replicación del ADN como la transcripción y la traducción. Gracias a estos mecanismos, la información genética puede transmitirse y expresarse con un grado muy elevado de fidelidad. Esta precisión es indispensable para mantener la integridad funcional de las proteínas y garantizar la supervivencia celular.
La característica estructural según la cual existen aproximadamente 10 pares de bases por cada vuelta completa de la doble hélice contribuye a la estabilidad y organización espacial del ADN. Esta configuración facilita el empaquetamiento de enormes cantidades de información genética dentro del reducido volumen nuclear y permite la interacción ordenada con proteínas reguladoras, enzimas replicativas y complejos transcripcionales.
Los genes controlan la síntesis de las proteínas porque almacenan la información genética en la secuencia específica de nucleótidos del ADN. Mediante los procesos coordinados de transcripción y traducción, dicha información se convierte en secuencias precisas de aminoácidos que originan proteínas funcionales. Estas proteínas son responsables de prácticamente todas las actividades celulares, incluyendo el metabolismo, la señalización, el transporte molecular, la contracción muscular, la defensa inmunitaria, la regulación génica y el mantenimiento estructural de los tejidos. Por ello, el ADN nuclear constituye el sistema central de almacenamiento y transmisión de información biológica que dirige el funcionamiento integral de los organismos vivos.


Fuente y lecturas recomendadas:
- Alberts, B., Johnson, A., Lewis, J., Morgan, D., Raff, M., Roberts, K., & Walter, P. (2022). Molecular Biology of the Cell (7th ed.). W. W. Norton & Company.
- Crick, F. H. C. (1970). Central dogma of molecular biology. Nature, 227(5258), 561–563. https://doi.org/10.1038/227561a0
- Jacob, F., & Monod, J. (1961). Genetic regulatory mechanisms in the synthesis of proteins. Journal of Molecular Biology, 3(3), 318–356. https://doi.org/10.1016/S0022-2836(61)80072-7
- Kornberg, A., & Baker, T. A. (2005). DNA Replication (2nd ed.). University Science Books.
- Lodish, H., Berk, A., Kaiser, C. A., Krieger, M., Bretscher, A., Ploegh, H., Amon, A., & Martin, K. C. (2021). Molecular Cell Biology (9th ed.). W. H. Freeman.
- Meselson, M., & Stahl, F. W. (1958). The replication of DNA in Escherichia coli. Proceedings of the National Academy of Sciences, 44(7), 671–682. https://doi.org/10.1073/pnas.44.7.671
- Nirenberg, M. W., & Matthaei, J. H. (1961). The dependence of cell-free protein synthesis in E. coli upon naturally occurring or synthetic polyribonucleotides. Proceedings of the National Academy of Sciences, 47(10), 1588–1602. https://doi.org/10.1073/pnas.47.10.1588
- Watson, J. D., & Crick, F. H. C. (1953). Molecular structure of nucleic acids: A structure for deoxyribose nucleic acid. Nature, 171(4356), 737–738. https://doi.org/10.1038/171737a0
- Wilkins, M. H. F., Stokes, A. R., & Wilson, H. R. (1953). Molecular structure of deoxypentose nucleic acids. Nature, 171(4356), 738–740. https://doi.org/10.1038/171738a0
- Zamecnik, P. C., & Hoagland, M. B. (1958). A relationship between soluble ribonucleic acid and protein synthesis. Proceedings of the National Academy of Sciences, 44(1), 73–82. https://doi.org/10.1073/pnas.44.1.73
Aprende administración paso a paso

ADMINISTRACION DESDE CERO