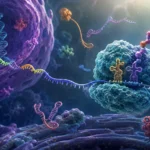
El ARN mensajero constituye la molécula intermediaria fundamental entre la información genética almacenada en el ADN y la síntesis de proteínas. Su función consiste en transportar una copia temporal de la información codificada en los genes hacia los ribosomas, donde dicha información será interpretada para ensamblar aminoácidos en una secuencia específica y formar una proteína funcional. Las moléculas de ARN mensajero son generalmente monocatenarias, es decir, están constituidas por una sola cadena de ribonucleótidos. En las células eucariotas, una vez sintetizadas en el núcleo mediante el proceso de transcripción, son sometidas a diversas modificaciones postranscripcionales antes de ser transportadas al citoplasma, donde permanecen en solución acuosa interactuando con proteínas reguladoras y con los complejos ribosómicos responsables de la traducción. La longitud de estas moléculas es extremadamente variable y puede oscilar desde varios cientos hasta miles de nucleótidos, dependiendo del tamaño del gen que representan y de la complejidad de la proteína que codifican.
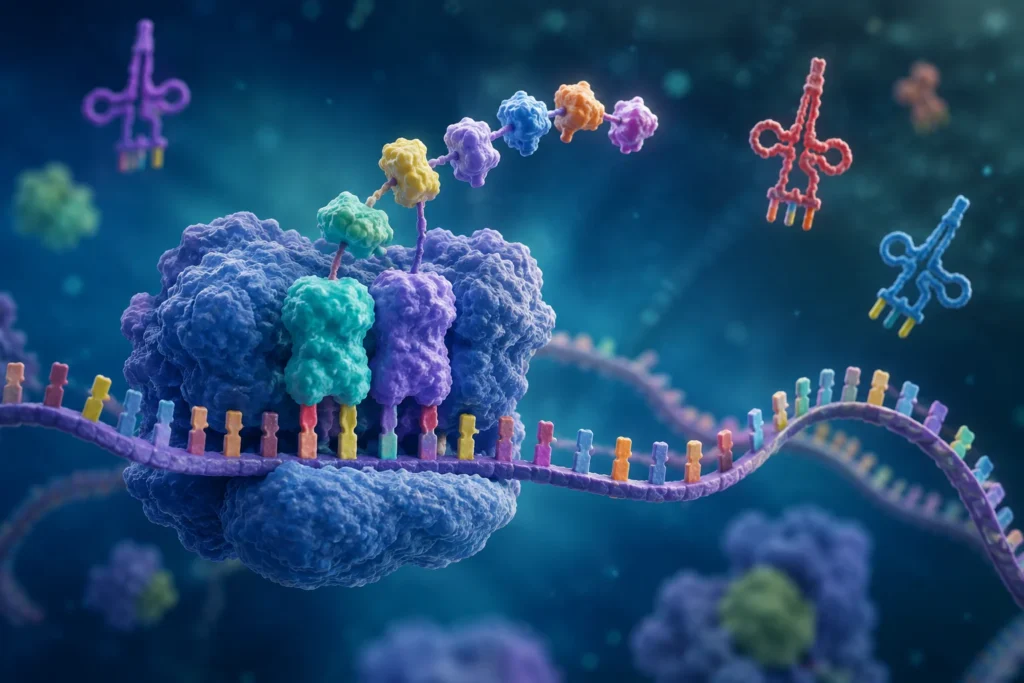
La información genética contenida en el ARN mensajero se organiza en unidades denominadas codones. Un codón es una secuencia de tres nucleótidos consecutivos que especifica la incorporación de un aminoácido determinado o transmite una señal funcional durante la traducción. La existencia de codones de tres nucleótidos surge de una necesidad matemática y biológica. El ARN utiliza cuatro bases nitrogenadas diferentes: adenina, uracilo, citosina y guanina. Si cada aminoácido estuviera codificado por una sola base existirían únicamente cuatro combinaciones posibles, cantidad insuficiente para especificar los 20 aminoácidos utilizados en la síntesis proteica. Si se emplearan dos bases consecutivas, solamente podrían generarse 16 combinaciones distintas. En cambio, utilizando grupos de tres nucleótidos es posible formar 64 combinaciones diferentes, número suficiente para codificar todos los aminoácidos y además proporcionar señales especiales de inicio y terminación de la traducción. Esta organización triplete constituye una característica universal del código genético en prácticamente todos los organismos conocidos.
Los codones del ARN mensajero son complementarios a la secuencia molde de ADN utilizada durante la transcripción. Durante este proceso, la ARN polimerasa sintetiza una molécula de ARN cuyas bases se aparean de forma complementaria con la cadena molde de ADN. Como consecuencia, la secuencia del ARN mensajero es prácticamente idéntica a la de la cadena codificante de ADN, con la única diferencia de que el uracilo sustituye a la timina. Esta relación de complementariedad garantiza la transferencia precisa de la información genética desde el gen hasta la maquinaria traduccional.
La lectura de los codones se realiza en una dirección específica, desde el extremo 5’ hacia el extremo 3’ del ARN mensajero. Los ribosomas avanzan a lo largo de la molécula interpretando sucesivamente cada triplete de nucleótidos. La posición donde comienza esta lectura resulta crítica porque determina el marco de lectura. Un desplazamiento de un solo nucleótido modifica completamente la agrupación de los tripletes y altera la secuencia de aminoácidos resultante. Por esta razón, los mecanismos celulares han evolucionado para identificar con gran precisión el sitio exacto donde debe iniciarse la traducción.
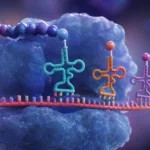
Cada codón es reconocido por una molécula específica de ARN de transferencia. Estas moléculas actúan como adaptadores moleculares que conectan el lenguaje nucleotídico del ARN mensajero con el lenguaje aminoacídico de las proteínas. En uno de sus extremos transportan un aminoácido concreto y en otro poseen una secuencia denominada anticodón, capaz de aparearse de manera complementaria con el codón correspondiente del ARN mensajero. La interacción precisa entre codones y anticodones asegura que cada aminoácido sea incorporado en la posición correcta de la proteína en crecimiento.
El código genético presenta una característica denominada degeneración o redundancia. De los 64 codones posibles, solamente 20 aminoácidos deben ser especificados. Como consecuencia, la mayoría de los aminoácidos están codificados por varios codones diferentes. Por ejemplo, la leucina está representada por seis codones distintos, mientras que otros aminoácidos, como la metionina y el triptófano, poseen un único codón. Esta redundancia proporciona una importante ventaja biológica porque reduce el impacto potencial de determinadas mutaciones puntuales. En muchos casos, un cambio en un nucleótido puede generar un codón alternativo que continúa codificando el mismo aminoácido, fenómeno conocido como mutación silenciosa.
Aunque el código genético es redundante, también es inequívoco. Esto significa que cada codón individual especifica solamente un aminoácido o una señal funcional determinada. Un mismo codón nunca codifica dos aminoácidos distintos dentro del mismo sistema de traducción. Esta propiedad garantiza la fidelidad de la síntesis proteica y contribuye a la conservación de las funciones celulares.
Otra característica fundamental es la casi universalidad del código genético. Los mismos codones suelen especificar los mismos aminoácidos en bacterias, arqueas, plantas, hongos y animales. Esta notable conservación evolutiva constituye una de las evidencias más sólidas de que todos los organismos actuales comparten un origen evolutivo común. Existen algunas excepciones limitadas, principalmente en genomas mitocondriales y en ciertos microorganismos, pero la estructura básica del código permanece extraordinariamente conservada.
Entre los 64 codones posibles existe un codón especializado que señala el inicio de la traducción. En la mayoría de los organismos, este codón es AUG. Además de actuar como señal de inicio, AUG codifica el aminoácido metionina. Cuando el ribosoma reconoce este codón en un contexto molecular apropiado, establece el marco de lectura correcto e inicia la síntesis de la cadena polipeptídica. La identificación precisa del codón de iniciación constituye uno de los pasos reguladores más importantes de la expresión génica, ya que determina dónde comenzará la producción de la proteína.
El codón de iniciación no funciona de manera aislada. En las células eucariotas, el ribosoma reconoce inicialmente la estructura de caperuza situada en el extremo 5’ del ARN mensajero y posteriormente explora la molécula hasta encontrar un codón AUG rodeado por secuencias favorables para el inicio de la traducción. Este mecanismo aumenta la precisión y disminuye la probabilidad de que la síntesis proteica comience en una posición incorrecta.
Además del codón de iniciación existen tres codones especializados que indican la terminación de la traducción. Estos codones son UAA, UAG y UGA. A diferencia de los codones que especifican aminoácidos, los codones de terminación no son reconocidos por ARN de transferencia cargados con aminoácidos. En su lugar, son identificados por proteínas denominadas factores de liberación. Cuando uno de estos codones alcanza el sitio funcional del ribosoma, los factores de liberación inducen la separación de la cadena polipeptídica recién sintetizada, provocan la disociación del complejo de traducción y permiten que el ribosoma pueda reutilizarse en nuevos ciclos de síntesis proteica.
Los codones de terminación desempeñan una función esencial en la integridad estructural y funcional de las proteínas. Si la traducción continuara más allá del punto correcto, se añadirían aminoácidos adicionales que podrían alterar el plegamiento de la proteína, modificar su estabilidad o interferir con su actividad biológica. Por esta razón, la identificación eficiente de los codones de terminación resulta tan importante como el reconocimiento del codón de iniciación.
La disposición secuencial de codones a lo largo del ARN mensajero constituye la base molecular mediante la cual la información genética se transforma en estructura proteica. Cada triplete representa una instrucción específica dentro de un lenguaje bioquímico altamente organizado. La sucesión ordenada de estos codones determina la secuencia primaria de aminoácidos, la cual condiciona posteriormente el plegamiento tridimensional de la proteína, sus propiedades fisicoquímicas, sus interacciones moleculares y, en última instancia, sus funciones biológicas. De este modo, los codones representan el vínculo fundamental entre la información hereditaria contenida en los genes y las características estructurales y funcionales que definen a los organismos vivos.


Fuente y lecturas recomendadas:
- Crick, F. H. C. (1968). The origin of the genetic code. Journal of Molecular Biology, 38(3), 367–379. https://doi.org/10.1016/0022-2836(68)90392-6
- Kozak, M. (1987). An analysis of 5’-noncoding sequences from 699 vertebrate messenger RNAs. Nucleic Acids Research, 15(20), 8125–8148. https://doi.org/10.1093/nar/15.20.8125
- Kozak, M. (1999). Initiation of translation in prokaryotes and eukaryotes. Gene, 234(2), 187–208. https://doi.org/10.1016/S0378-1119(99)00193-6
- Nirenberg, M. W., & Matthaei, J. H. (1961). The dependence of cell-free protein synthesis in E. coli upon naturally occurring or synthetic polyribonucleotides. Proceedings of the National Academy of Sciences, 47(10), 1588–1602. https://doi.org/10.1073/pnas.47.10.1588
- Sonenberg, N., & Hinnebusch, A. G. (2009). Regulation of translation initiation in eukaryotes: Mechanisms and biological targets. Cell, 136(4), 731–745. https://doi.org/10.1016/j.cell.2009.01.042
- Watson, J. D., & Crick, F. H. C. (1953). Genetical implications of the structure of deoxyribonucleic acid. Nature, 171(4361), 964–967. https://doi.org/10.1038/171964b0
- Woese, C. R. (1965). On the evolution of the genetic code. Proceedings of the National Academy of Sciences, 54(6), 1546–1552. https://doi.org/10.1073/pnas.54.6.1546
- Yarus, M. (2021). The genetic code and RNA-amino acid affinities. Life, 11(9), 899. https://doi.org/10.3390/life11090899
Aprende administración paso a paso

ADMINISTRACION DESDE CERO